

NLP project series: Building an advanced Substack newsletter understanding tool
Come follow me as I build an NLP project from scratch!
Hello everyone!
I am excited to share with you the next series of posts on the Human Language Technology substack. This series of posts will be a hands-on walkthrough covering the entire development of the realistic Natural Language Processing (NLP) project from scratch.
As we are nearing the end of the year, it is a great time to start upgrading your skills. The major holidays are coming, plus many companies are wrapping up their goals for the year, which leaves us more time to develop our skills.
On top of that, the large majority of tech companies are not hiring until the beginning of next year, which gives us an opportunity to improve our skills and build our resumes before interviews start.
Let’s get into it!

Quick interruption from the current post:
I want to make two shout-outs to the readers of the newsletter.
First, would love to give a shout-out to the Bot Eat Brain AI newsletter that covers hot news and memes of things happening in AI.

Second, one of the readers of Human Language Technology substack Thobey Campion kindly asked me to share the job posting for the start-up that he is building.
He is sharp fella based on our conversation and he built Vice Media in NYC. If you are more experienced in the NLP space and looking for an opportunity to build an early stage startup talk to him.

Project Description
We will build the Substack newsletters understanding tool. This tool will help you analyze, search, and recommend Substack newsletters through the power of natural language processing.
Going into a bit more detail we will build a tool that:
Analyzes and visualizes all the newsletters available on Substack.
Searches newsletters based on the semantic meaning of the text.
Recommends the newsletters to follow based on the newsletters we like.
It sounds like a lot, but at the core of it, we will rely on the single human language technology (hint: embeddings) in order to solve the majority of the tasks.
Tacking this problem
Get an unscripted look at how I tackle real NLP problems by subscribing to my newsletter series.
You'll see how I break down the task into multiple steps with approximate timelines and risks associated with each task. This type of straightforward project tracking has served me well both for personal projects and in my career.

This is a rough estimate. We will change and add tasks as we go along. We will explain it in more detail as we dive deeper into each task.
Step 1: Data Collection
We need to collect data related to Substack newsletters before we can even start modeling. Specifically, we need to get some information about each substack newsletter. Things that immediately come to mind are:
Substack name
About page (description)
Posts
We do not need to hire human annotators to collect such information. This process can be automated by scraping data from the Substack website itself.
Note: NLP is a critical piece of the puzzle when it comes to building successful projects - but it's only one part of the equation. You also need to invest time and energy into collecting and cleaning data, analyzing results, and refining your approach until you achieve the desired outcome.

Scraping Substack
Let’s get into the technicals. The overall process of scraping data from Substack can be expressed in the following pseudo-code:
Get all available Substack newsletters. The newsletter will be in the form of
xyz.substack.com(examplelanguagetech.substack.com)For each substack:
Get the name and description of the substack from
/aboutpageScrape information from the posts in that particular substack newsletter
Now as for the exact implementation I will be following the things I learned from the excellent Ryan Kulp’s course on fundamentals of web scraping.
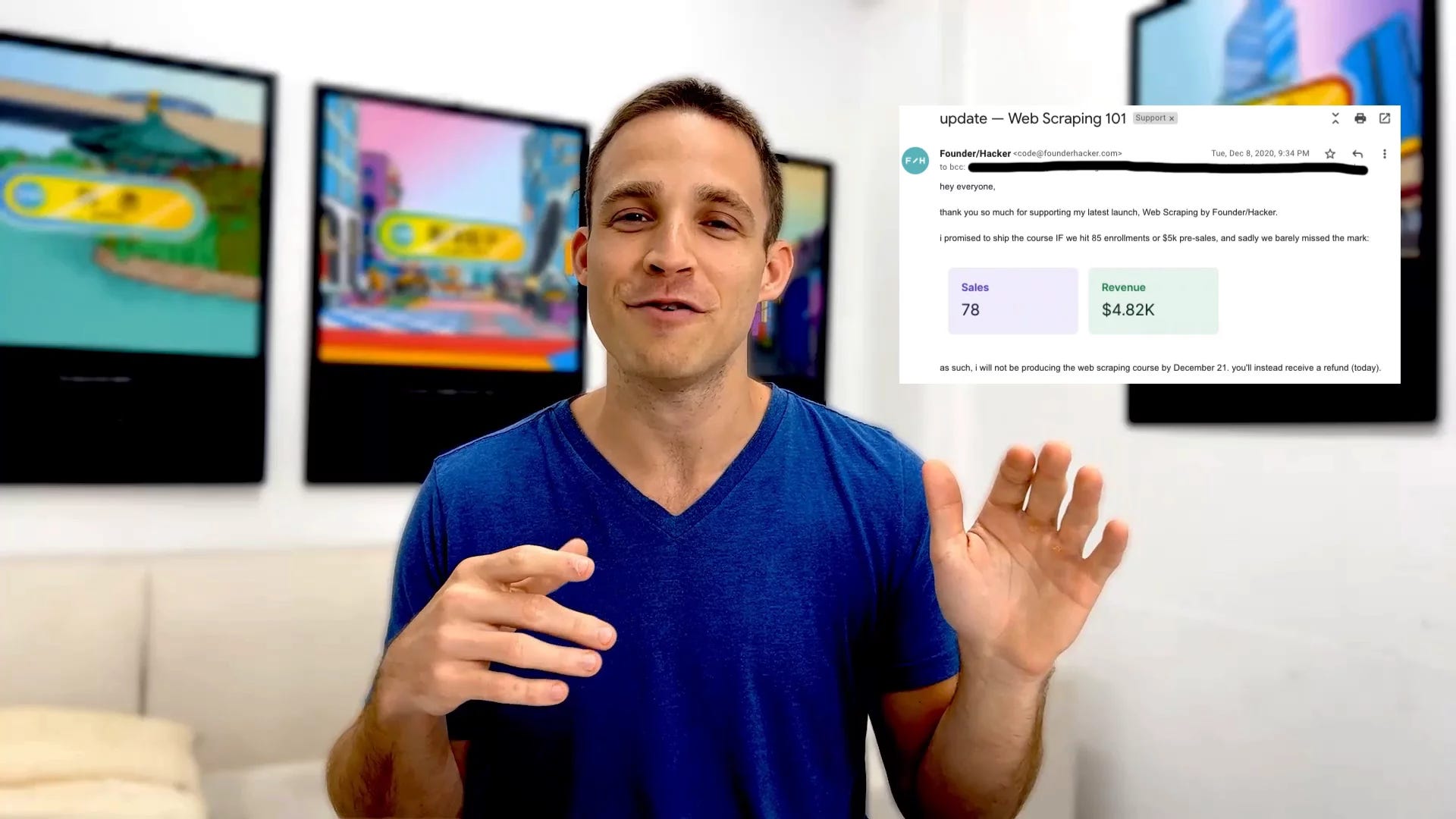
The course takes a few hours and covers the entire process of building a web scraper for Shopify app listings. Ryan uses Ruby which is a programming language with a similar scripting flavor to Python.
Ruby is particularly useful for building web apps and I am personally planning to dive deeper into it in the following months (Ryan has another great course coming soon on that).
In this post, I will go over the key concepts from the web scraping 101 courses that I learned and apply them to our problem of scraping Substack newsletters.
Getting all newsletters
Getting an entire list of newsletters from Substack turned out to be very straightforward.
We are going to take advantage of the XML sitemap, that lists a website’s essential webpages to make sure that Google can crawl, index, and find them. All the newsletters are listed in the XML under the https://substack.com/sitemap-tt.xml.gz link.
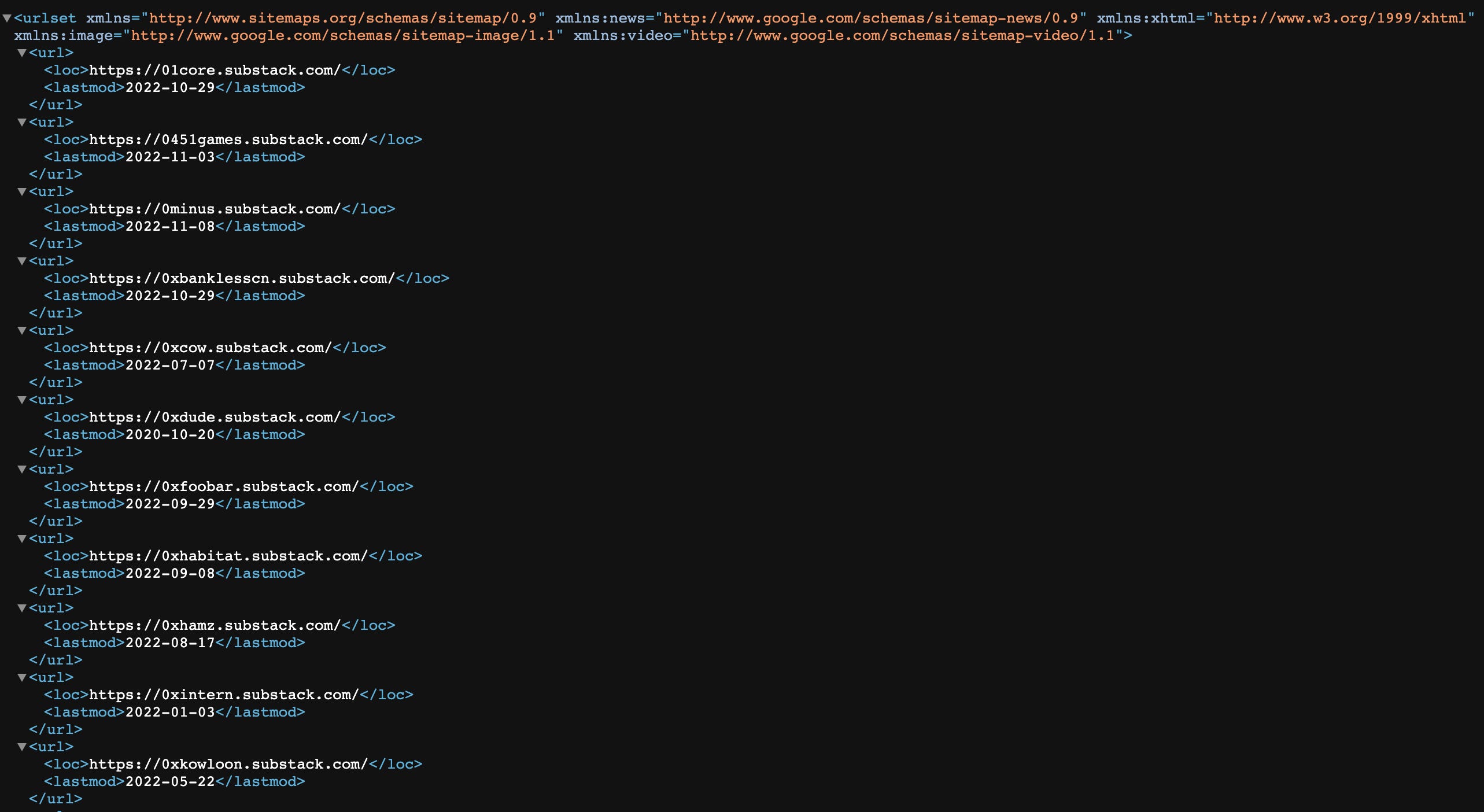
Implementation-wise it is very straightforward in Ruby (I will provide the entire code and instructions to install relevant libraries at the end of the post).
def get_all_substacks
# function that gets all the substacks from the SITEMAP_URL
# open url
puts "Opening #{SITEMAP_URL}"
page = URI.open(SITEMAP_URL)
puts "Done opening #{SITEMAP_URL}"
# parse this page
xml = Nokogiri::XML(page)
# get all urls from xml
urls = xml.css('loc').map {|link| link.text}
# save the urls to the all_substacks array
@all_substacks = urls
# save all_substacks to csv
save_to_csv
end
def save_to_csv
# function that saves all_substacks to a csv file
# create csv file
CSV.open('substack_newsletters.csv', 'wb') do |csv|
# add all_substacks to csv
csv << @all_substacks
end
endI save all the newsletter links to the substack_newsletters.csv file and use this file to crawl all the newsletters.
Crawling about pages and posts for each substack
We will be using the information in the about pages and posts to form general information about each substack.
Crawling information from the About page is a matter of going into the substack_link/about and extracting text content from it in the form of <h1>, <h2>, <h3>, <h4> (headings), and <p> (paragraph) tags.
Code:
def get_substack_description(substack_url)
# open substack_url / about page
@browser.goto substack_url + '/about'
# get div under class 'content-about'
div = @browser.div(class: 'content-about')
# for each element in div if it is either h or p add it to string
description = ''
div.elements.each do |element|
if element.tag_name == 'h1' || element.tag_name == 'h2' || element.tag_name == 'h3' || element.tag_name == 'h4' || element.tag_name == 'p'
# add element to description with new line
description += element.text + '\n'
end
end
description
end
As for crawling posts for each substack, we use the same logic as for originally crawling all the links to substack newsletters. Each substack newsletter also has its own sitemap.xml that contains all the links to the posts in the easy-to-parse XML format.

The posts are sorted by date, making the most recently published posts available at the top of the XML file. Ideally, we would go into each link and crawl the relevant information from it (title and main body of text).
However, we are constrained by the fact that Substack can throttle us and restrict us from further crawling other substacks if we enter too many links from the same IP. On top of that, some of the Substacks have a lot more posts than others which would make us spend a disproportionate amount of time crawling them.
Going around:
Let’s make an assumption that the 5 latest posts from each substack are enough to get the post information. We will only retrieve the title from each post, without the paragraphs inside.
This assumption may hurt me down the line once I start doing analysis, search, and recommendation of substacks. But I prioritize speed of iteration to perfection in execution. If it indeed hurts the quality of results down the line, we will come back and crawl more information from posts.
Code:
def get_all_post_titles(substack_url)
# get sitemap url
sitemap_url = substack_url + 'sitemap.xml'
# get sitemap xml
sitemap_xml = Nokogiri::XML(URI.open(sitemap_url))
# get all post titles
# for each sitemap url open it if it is not "/about" or "/archive"
# get all h1 titles and save them to an array
post_titles = []
sitemap_xml.css('loc').each do |link|
# scrape first 5 posts
break if post_titles.length >= 5
# if exception continue
begin
# get url
url = link.content
# if url is not about or archive
if url.include?('/about') || url.include?('/archive')
next
end
# open url
@browser.goto(url)
# get the h1 title under class 'post-title'
title = @browser.h1(class: 'post-title').text
# add h1 title to post_titles array
puts url, title
post_titles << title
# sleep for 4 seconds to prevent timeout
sleep 4
rescue => e
puts "Error scraping #{url}; error message #{e.message}"
end
end
puts "Found #{post_titles.length} post titles for #{substack_url}"
puts post_titles
post_titles
endNext Steps
As I wrote these key pieces of code, I started scraping Substack.
Challenge: But as I started scraping it, I hit the problem. Substack started timing out my requests after accessing few pages. Adding a 4 second timeout between opening each page solved them problem, but it turn made scraping too slow. I managed to scrape roughly ~1,500 newsletters out of ~27,000 in total during 24 hours. This is too slow for me.
How to go around it?
I will be trying rotating proxies to make scraping faster. This is my first time trying rotating proxies so I am looking forward to it and sharing my experience with you in the next post🫡
Early impressions of the data
I noticed that a good number of substacks do not update their About page. An extra care should be necessary to clean up such newsletters and process them appropriately (missing About page) with NLP model.
But that’s for another time.
If you would like to take an early look at the whatever data I scraped so far take a look at CSV here (LINK). Each row is a substack newsletter. First row is a substack newsletter link, second row is the description from about page, and the following 5 rows are the titles of latest 5 posts.
Code and steps to reproduce this post
Code LINK
Make sure to set the path to AWS S3 Bucket correctly on line 77 if plan to back up data to AWS.
Steps to install the libraries (like headless browser and chromedriver) LINK
Go over the Ryan’s course section on installing libraries and reach out if you have any problems.
See you next week! If you liked this post, please smash the like button and recommend it to your friends. Let me know if thoughts in the comments as well.
Hal, I know this is just the start of your project, but this post is really incredible. To get this kind of step-by-step insight and to be metaphorically looking over your shoulder as you do this is unbelievably educational, insightful, and just damn fascinating.
Your Substack is can’t miss material.
Realistic NLP from scratch caught my eye. How about data preperation?